on
Building GHC: The Stages
In part one we learned about the package database. Part two then introduced the tools and programs built when building GHC. In this part we will look at how the actual stages are built. I will not go into the detail of the make based build system, but try to give an overall understanding what is happening conceptually.
To build GHC usually involves running:
./boot (1)
./configure --prefix=/usr/opt (2)
make -j (3)
make install (4)
Let’s break down what is happening here: running =./boot= generates
ghc.mk make files throughout the source tree unless the folder already
contains one. It also runs autoreconf where necessary (e.g. if there
exists a configure.ac file, autoreconf is run to turn those into
configure scripts for the respective libraries).
The next step, running =./configure= (which can be take a few
parameters, see =./configure –help=) runs a battery of detection
functions to collect information about the machine GHC is built
on. This includes but is not limited to paths to tools, the
architecture, operating system, if the system builds Position
Independent Executables by default, and more. The collected results
will then be substituted in =.in= files in the build system producing
files without the =.in= extension where those values are embedded
(e.g. turns settings.in into settings).
At this point we now have primed the source tree to contain the necessary build (and possibly target specific) information to be used throughout building GHC.
make will then run the make build system to produce ghc, the package
database to be shipped with ghc and other utilities (e.g. ghc-pkg).
Finally make install will move those into place, which would be
/usr/opt in the example above. At this point the GHC build system is
done.
With that out the door, let’s take a closer look what make actually
does. GHC is built in stages. And there are usually three stages
involved. We build the stage 1 compiler with the stage 0 compiler, and
the stage 2 compiler with the stage 1 compiler.
Stage 0 is the bootstrap stage. The bootstrap stage is built by the bootstrap ghc this is the GHC that is already present on the system. The bootstrap ghc comes with it’s package database that was installed when the bootstrap compiler was installed.
Building the stage 1 compiler
As the compiler quite often depends on features of libraries it depends on that are not guaranteed to be new enough in the bootstrap compilers package database, the first step is to augment the bootstrap compilers package database with those required packages to build the Stage 1 compiler. To do this, we compile this set of bootstrap packages with the bootstrap compiler.
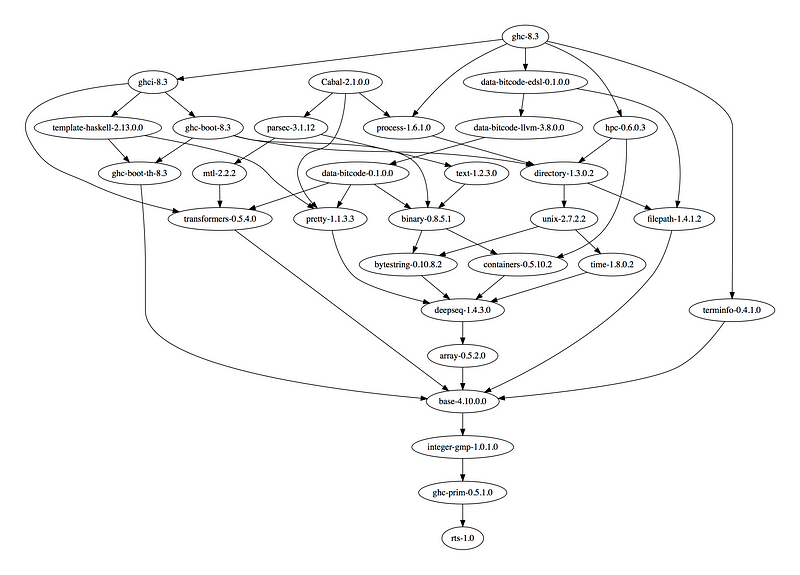
Figure 1: My stage0 package database.
Note: my stage 0 package database contains the data-bitcode-* packages
which make up my llvm-ng backend.
From the base version 4.10.0.0 we can infer that this is likely the
package database that was shipped with ghc 8.2.1.
The ghc-8.3 package will not be in the package database initially,
however we can see that all it’s dependencies are part of the package
database. As such building the actual ghc executable with the
bootstrap compiler is now possible. So we move on to build ghc,
ghc-pkg, hsc2hs and other tools with the bootstrap compiler. These
together with the the augmented bootstrap package database constitute
the stage 1 now.
Building the stage 2 compiler
With the stage 1 compiler, and the augmented bootstrap package
database, we proceed by compiling all libraries that ship with GHC and
register them in the stage 1 package database (these are packages
built with the stage 1 compiler). And we finally build the ghc with
the stage 1 compiler as well as other utilities we want to ship with
the stage 2 compiler.
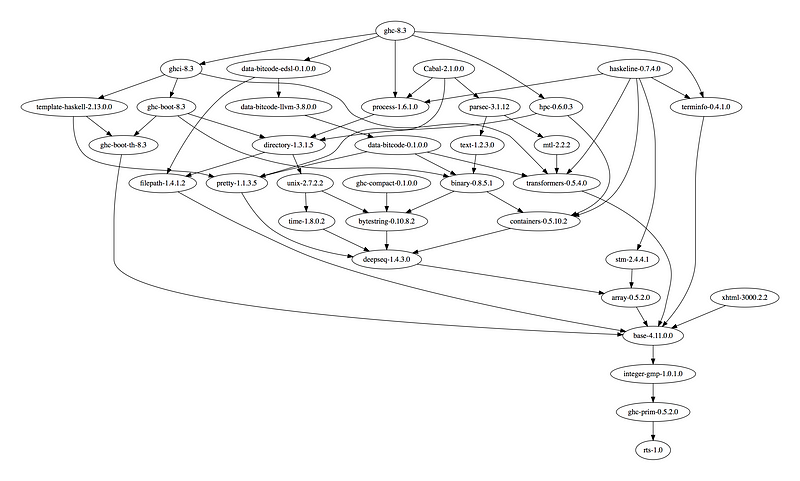
Figure 2: My stage1 package database.
We could now iterate this process again and obtain a stage 3 compiler built with the stage 2 compiler, or go on and build and register additional packages into the stage 1 package database with the stage 2 compiler. I hope the idea and approach should be sufficiently illustrated at this point.
So why did we need to build the compiler twice, wouldn’t the stage 1 compiler and the stage 1 package database have been enough? That’s a good question! We need to build the stage 2 compiler with the stage 1 compiler using the stage 1 package database (the one we will ship with the stage 2 compiler). As such, the compiler is built with the identical libraries that it ships with. When running / interpreting byte code, we need to dynamically link packages and this way we can guarantee that the packages we link are identical to the ones the compiler was built with. This it is also the reason why we don’t have GHCi or Template Haskell support in the stage 1 compiler.
A binary distribution
To build a binary distribution from our final stage 2 compiler we only
need the ghc (built with the stage 1 compiler which was built with the
bootstrap compiler) together with the stage 1 package database (built
with the stage 1 compiler). There is some additional packaging logic,
which I will not go into, but only mention: we package an additional
configure script to adapt the system on which GHC will ultimately be
installed, and make sure the wrapper scripts around GHC all contain
the correct absolute paths, and additional files (e.g. settings) are
included in the binary distribution as well.
This completes this mini series on Building GHC. If you have further questions, please ask!